如何运用ABBYY FineReader识别图片中的文本
作为一款OCR光学字符识别软件,ABBYY FineReader能够快速方便地将扫描纸质文档、PDF文件和数码相机的图像转换成可编辑、可搜索的文本,让电脑处理更具效率,摆脱从前的烦恼,告别耗时费力的手动输入和文件编辑。今天就给大家分享一篇别人使用ABBYY FineReader识别图片中文本的案例,看别人是如何利用ABBYY FineReader提高效率的:
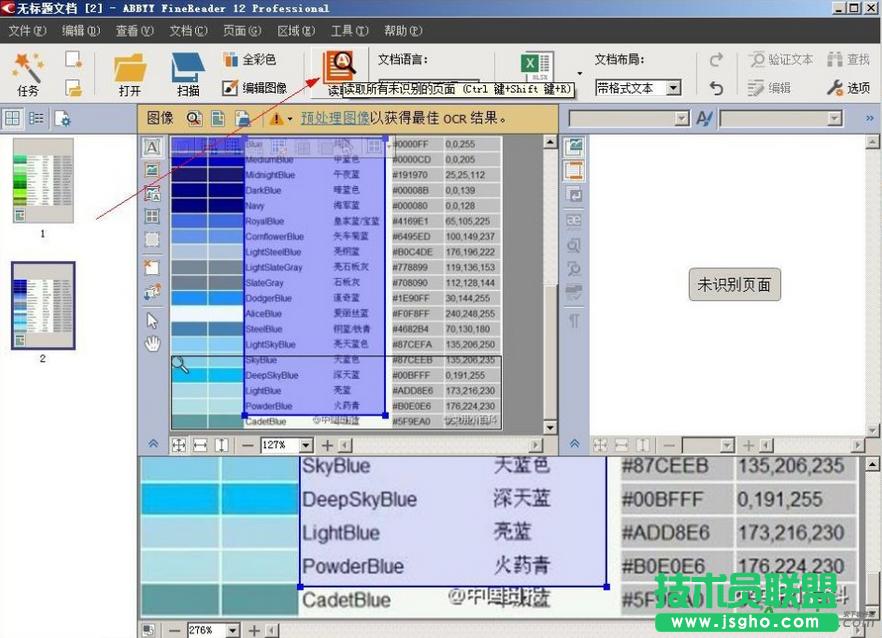
昨天在微博收藏了几张图片格式的中英文对照的色谱,以后翻译的时候可能会用到,因此想到通过OCR(光学文字识别)识别处理后导入CAT中备用。之前在微博经常看到各位大佬儿推荐ABBYY FineReader,提到它无与伦比的识别效果,今天小试牛刀,兴奋不已,效果确实不错,对中文字符的识别度较高,不啰嗦,上图说明撒。
准备:找到预先保存的两张jpg格式的图片,安装最新版ABBYY FineReader 12软件。
目标:提取图片中的英文和中文栏,导出Excel格式的文本。
原始图片
操作过程1、由于图片中的文本分列显示,因此打开ABBYY FineReader 12后,选择Microsoft Excel项;
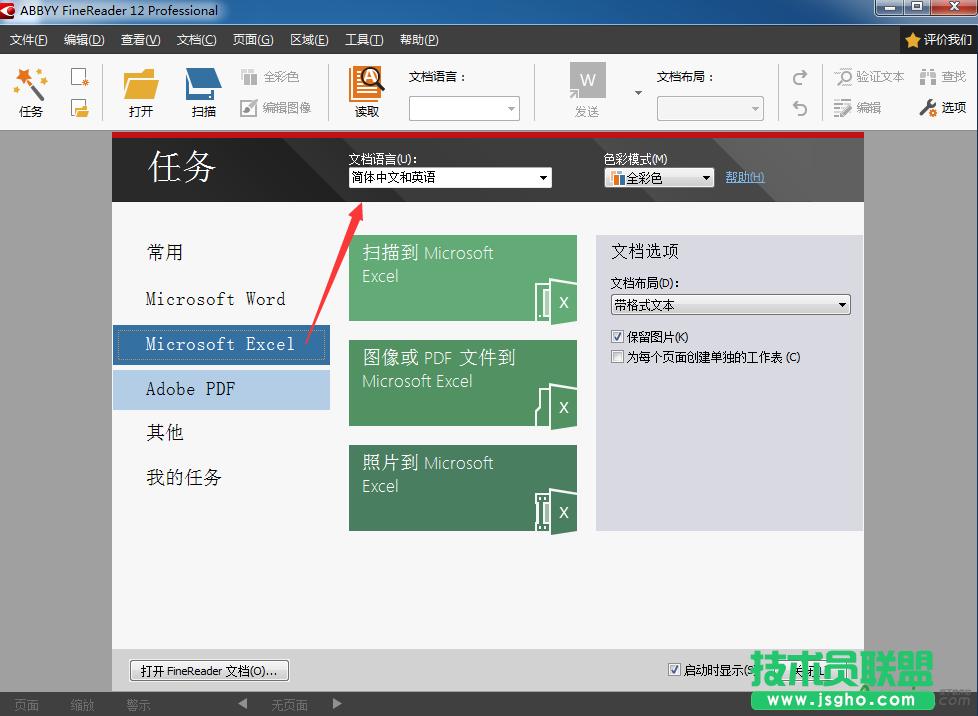
注:在这个窗口可以设置要识别的语言(简体中文和英文),以及色彩模式,这里可以选择全彩色和黑白模式,黑白模式的读取速度要稍快一些。
2、然后选择“图像或PDF文件到Microsoft Excel”,添加要识别的两张图片,打开后软件自动开始识别;也可以点击“文件”,新建一个文档,然后直接把要识别的图片拖放到软件左列,同样可以打开进行识别;
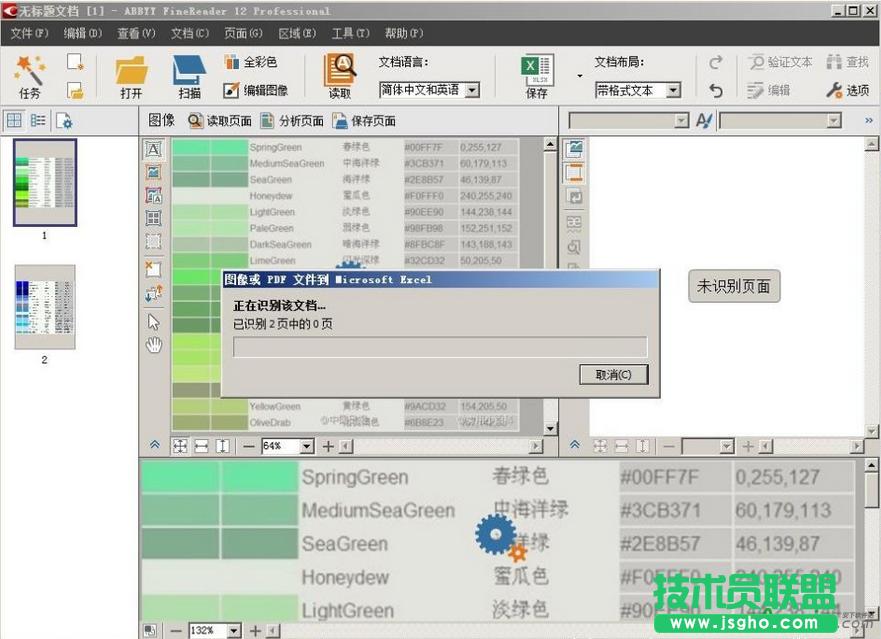
3、考虑到图片文字可能会出现模糊,文本歪斜和转向,因此选择取消识别,先对图片进行编辑处理,点击上面工具栏里的“编辑图像”,右侧打开编辑工具列表;
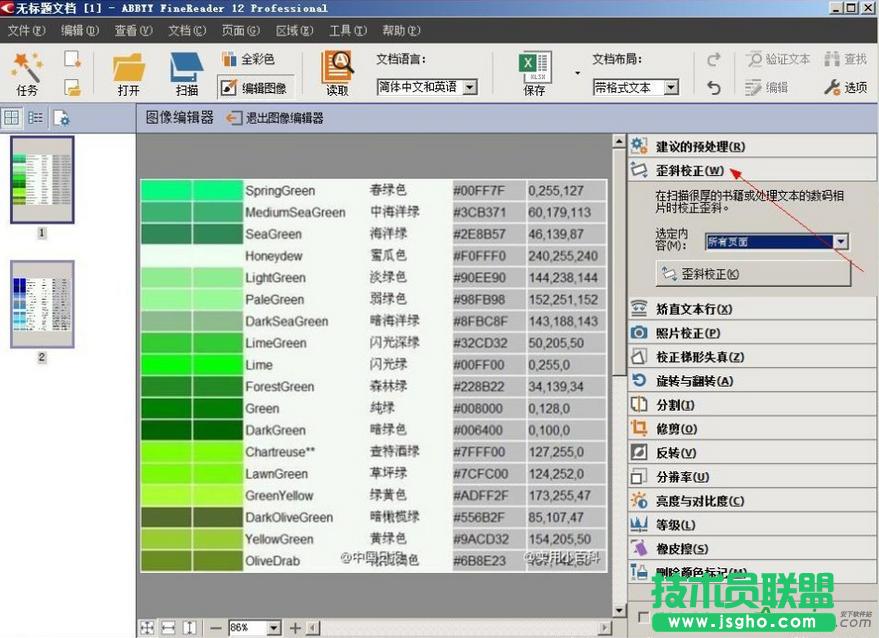
4、首先,要对图像进行歪斜校正,如扫描的图片不规整,在扫描后会提示对需要进行校正的图片进行歪斜校正,这里可以选定“全部页面”,然后点击“歪斜校正”;若图片是旋转90度或倒转后的图片,可在这里将其旋转或翻转处理;
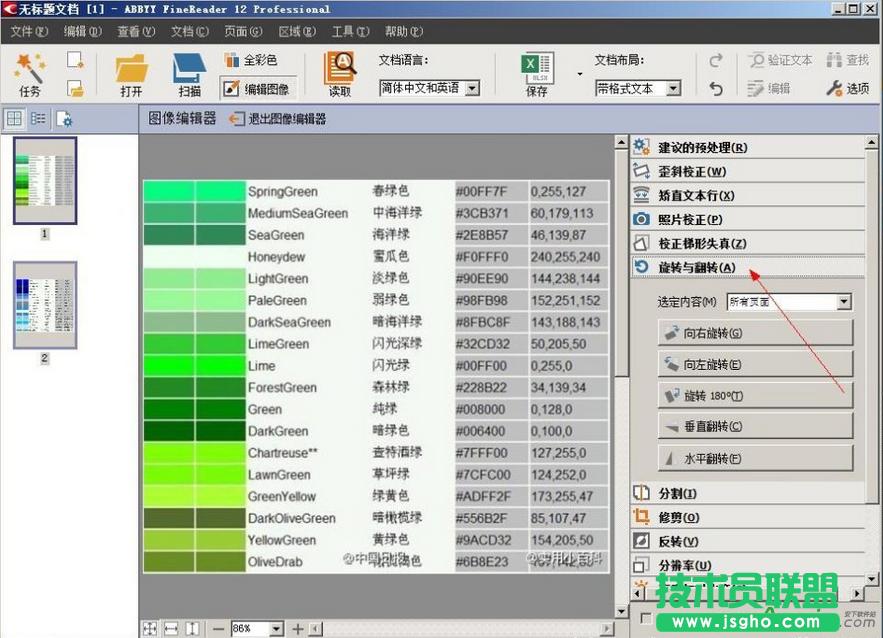
5、接下来,也是最重要的,就是调整图片的分辨率,有些图片模糊不清,会影响软件识别效果,这里可将图片的分辨率设为扫描图像的分辨率,即300dpi,这个值基本上都可以正常识别了,也可以自定义分辨率。通过这个选项,可分别单张设置图片的分辨率,也可以选奇数页或偶数页和全部页面,为了不影响识别,这里可以选择“所有页面”;
6、然后就可以退出图像编辑器;
7、由于我们只需要中英文对照的两列文本,其他无关的内容可以不进行识别,因此,可选择要识别的区域,即点击中间一栏左上角的“A”按钮,可选择两列要识别的文本;
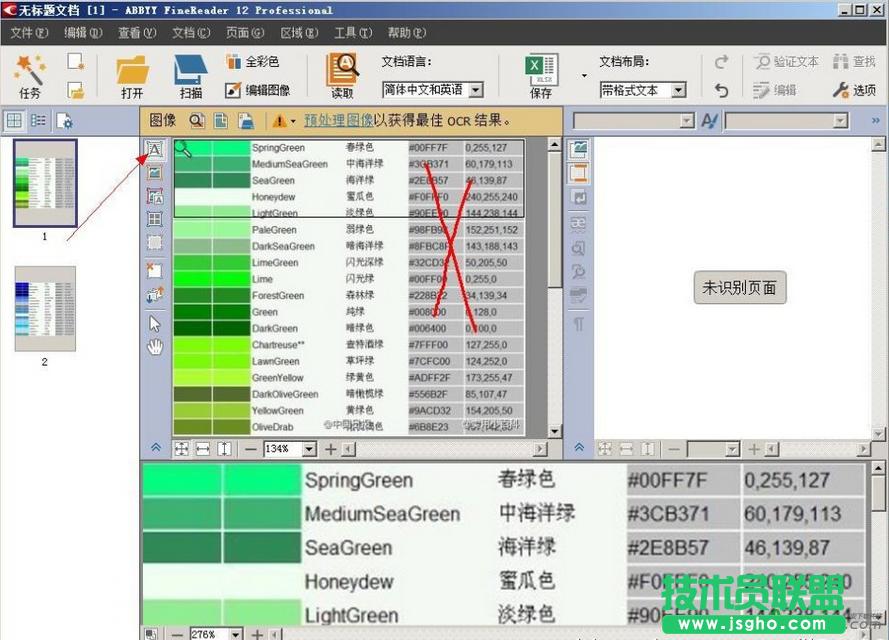
8、选定后的文本呈浅绿色,然后点击选中区域,在弹出的工具栏选择按钮“A”,找到里面的“表格”项,这样识别后的文本就成两列对照的文本了;
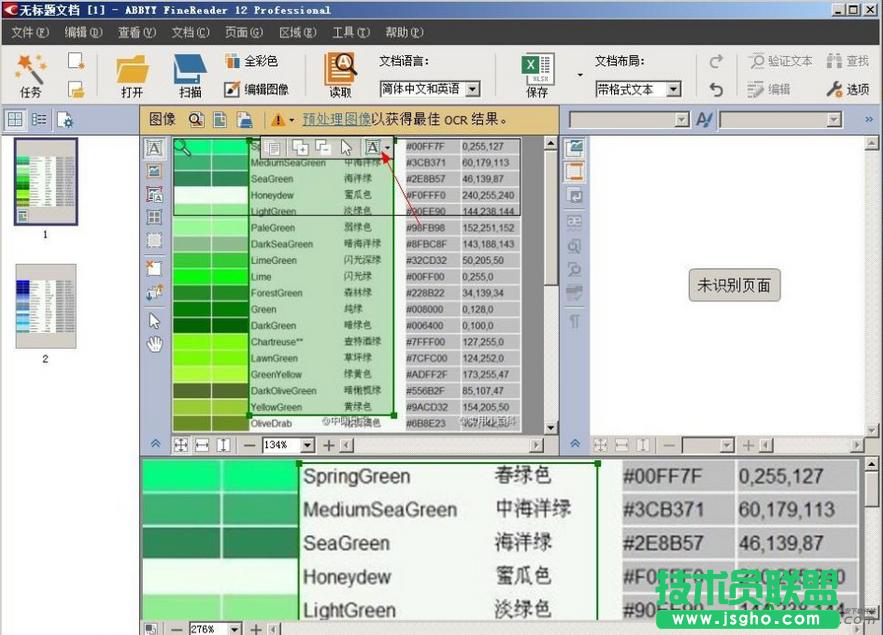
9、然后,点击上面工具栏里的“读取”选项,开始识别;
……